On Microservices (Chapter 6 - Journal Reader Services (continued))
3 of 4 - Journal Reader Services (cont.)
For reference, the 4 service types were:
- Noun
- Query
- Journal Reader
- Verb
With that Push versus Pull context in mind, let’s now examine the Journal Reader service.
— Journal Reader Services —
Here is an image showing a possible implementation of a Journal Reader:
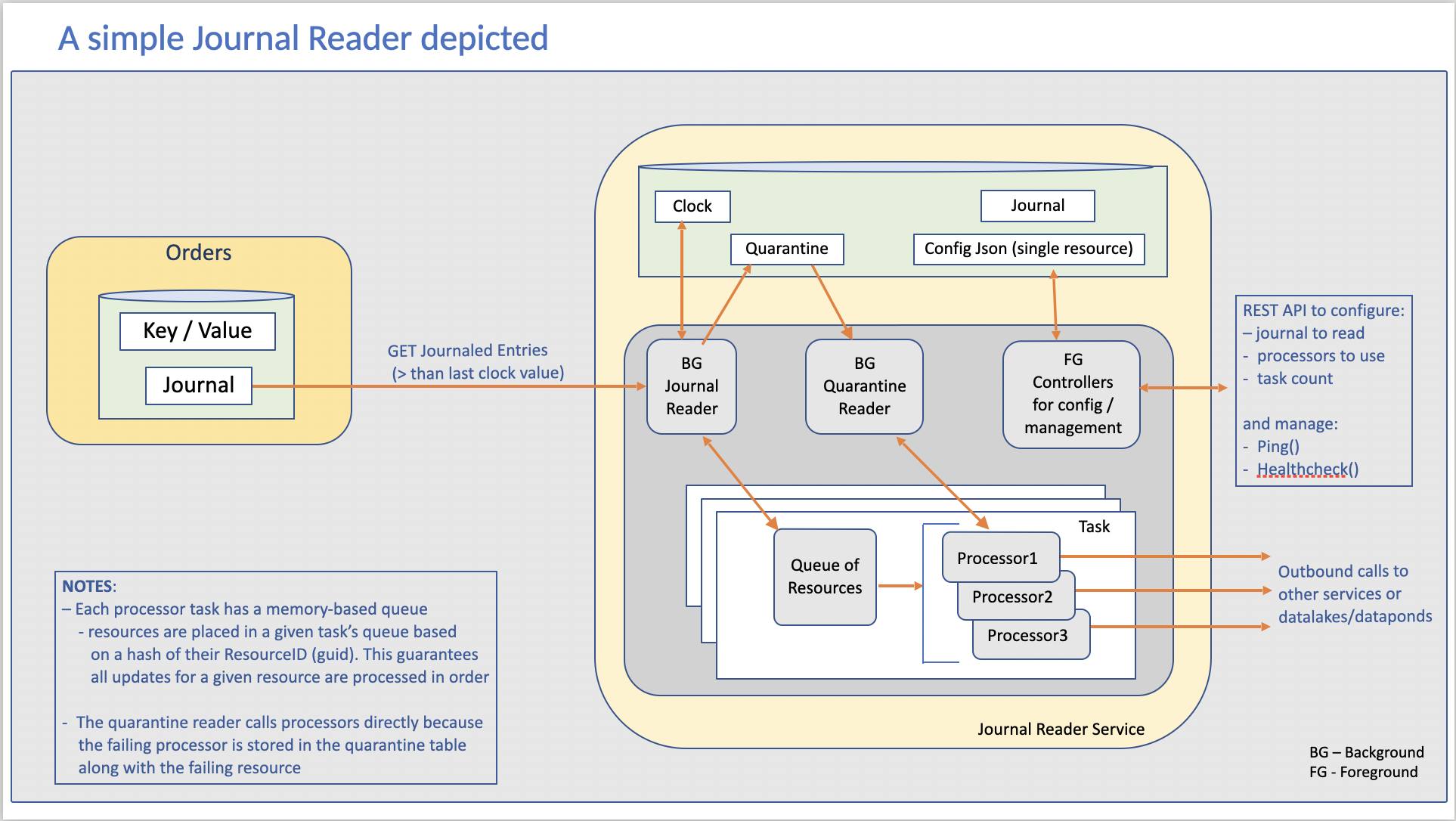
At a high level, the Journal Reader service does this:
The PULL
Each Journal Reader calls a noun service with a simple GET call to retrieve any resource entries appended to that noun’s journal table that are yet unprocessed (by this journal reader).
Here is a sample GET call from one of my Postman collections (Note: the “{{ }}” values are Postman env variables):
{{HTTP}}://{{ORDERS-HOSTPORT}}/v1/journal?clock=10950&limit=100
This call fetches up to 100 journaled entries from the orders service starting at the 10950th entry (because the earlier ones were already processed).
Key points:
- Every Journal Reader manages (persists) its own highest, last-read entry from a noun’s journal (called ‘clock’ in the URL above).
- This is easy to do because the journal tables include a monotonically increasing integer column that is incremented by the database on insert.
- The PULL (aka GET call) requests a batch of entries starting with the last processed entry as stored by the Journal Reader (ie. itself)
The PROCESSING
For each new entry retrieved, the Journal Reader makes a call to a list of pre-configured Journal Reader Processors
(Reminder: These entries are literally just the full, versioned JSON resources resulting from each update done on a given resource owned by a noun serivce)
Journal Reader processors are simple callable routines that expose a common API interface that is used by the journal reader to pass them a journaled entry. Their job is simple:
- process the entry successfully or return an error/exception for that entry (usually including the specific error detected)
Journal Reader processors are simple callbacks that can be used in many ways. Common uses include:
- calling other downstream services
- In the commerce example I’ve been using as an illustration, both the Subscriptions and Entitlements noun are called by Journal Reader Processors, passing a funded Order from which to create both a new Subscription and new Entitlement
- populating data lakes/ponds, etc.
- Processors that populate data lakes/ponds will commonly do the shredding of those JSON journal entries into the nicely queryable, indexed tables that the query service leverages.
- The fact that the Journal Reader is happy to call however many Processors you define allows for nice partitioning of this logic to simplify maintenance.
- THOUGHT EXERCISE: If you care about idempotency (and you should), Processors that populate data pond/lakes are a great place to put a simple piece of logic to provide for an idempotency guarantee. It takes a bit more work than this for Processors calling other downstream services (do you know why?), but it is doable there as well.
(NOTE: I’ve used the terms “data pond” and “data lake” a couple of times without delineating between them. Data Pond is an operational-focused (and usually smaller) Data Lake that is only used by apps issuing queries. Data Lake, on the other hand, is all about analytics and is generally configured for that purpose. Using a relational database with strong support for OLAP is common here. Alternatives with stronger analytics support (e.g. Snowflake) can also be leveraged.)
(A lower-level, implementation detail) Journal Reader processors typically run in a set of n (configured number) tasks that are spawned by the Journal Reader. Journaled resource entries (from the PULL above) being processed are divided up between the tasks using an algorithm (e.g. consistent hashing) to ensure that all updates for a given resource are processed in order.
When all entries from the GET have been processed, the Journal Reader ‘clock’ is transactionally updated to be the highest ‘clock’ processed so that processing of resources from the next PULL can begin.
The FAILURE/RETRY PROCESSING
Any entry not processed successfully by a journal reader processor will be inserted by the Journal Reader into a ‘Quarantined’ table preserving all of:
- the unprocessed journal entry
- the processor that failed to process it
- the error returned (ie. why it failed) by that processor.
But, this ‘Quarantined’ table is not a typical (read: lame) dead-letter queue like is found most queuing systems.
Differences:
- Any subsequent journal entry sharing the same resource-id as a resource currently in the Quarantined table will also be placed into the Quarantined table. This prevents processing later versions of a resource out-of-order.
- The Journal Reader has separate background thread(s) that retries (ie. calls the failing journal reader processor again) entries currently in the Quarantined table on the assumption that the problem causing the error will be resolved.
- Want to see what is failing? Just run a query on the Quarantined table. You will instantly know which entries failed, what processor logic failed them, and the error/exception thrown as part of that failure.
- Recommendation: Having background monitoring checking this table for count of entries, etc. with appropriate notifications to the right mix of OPS/Engineering/Other is very powerful.
Some will now say “This Journal Reader with Processors model sounds just like lambda or [insert favorite cloud function here]!”
But, upon examination, the journal reader models offers a lot more in terms of benefits:
-
The quarantine error recording & recovery semantic is stronger
-
The guarantee of in-order processing of resource updates (for both success and retries) is a big deal
- Each downstream or loose-coupled system using a journal reader pulls journaled entries at its own pace (both batch size and GET frequeuncy) while maintaining its own ‘clock’ for what has been processed so far from a noun’s journal.
- Customer product provisioners, as mentioned earlier, will typically be aggressive to ensure the customer’s product is available immediately after purchase
- Journal Readers that populate data ponds/lakes, which may not require up-to-second data, can be less aggressive and even process the journal off-hours when compute costs are cheaper.
-
You have full control of where Journal Readers are installled and run. They can be used to pull data across cloud boundaries and/or in on-prem data centers. Hybrid cloud, anyone?
-
Loose-coupled systems using journal readers can do maintenance (including taking their entire system down if they so desire), without forcing flow-control issues upstream, like were seen in the ‘push’ architecture model. When they start back up they will just continue where they left off as preserved in their ‘clock’ value.
- Again, all persistence is still wholly contained in the underlying relational database model.
- Simple backup/restore/failover/monitoring is still maintained
- Operations expertise, dev team expertise, and licensing are all cheaper
- Less moving parts means overall up-times are better.
- THOUGHT EXERCISE: I’ll just sneak this little tidbit in here for those paying close attention and already thinking about building/using the journaled microservivce model.
- Technically, a Journal Reader doesn’t have to call a noun service. It can, just as happily, pull journaled entries from a limited view of a noun’s journal that is (eg.) accessible via a query service.
- After all, the Journal Reader logic is simply doing a GET to whatever service its config indicates it should pull journaled entires from. As long as that configured service returns journaled entries in order it does not need to return them all.
This flexibility is great for: 1) limiting full journal access if needed 2) adding new Journal Reader Processors that need to catch up quickly 3) migrations that only need deal with a small subset of journaled entries 4) Etc. We can discuss more directly if anyone so desires.
We now have:
- Noun services with both current value and journaled changes
- Loose-coupled Journal Readers pulling from those journals at their own pace and which invoke Processors that either:
- call other services or
- populate data lakes/ponds
- Query Services that sit in front of those data lakes/ponds listening for and answering queries issued from front-end/back-end apps
That was a lot of verbiage. Let’s look at an illustration that shows usage.
In this illustration, tight-coupled services just call each other directly to accomplish a shared goal.
- Example: Front-end calls the Orders noun to make a purchase. This is shown below. Not shown below is: Orders calls Bills which calls Payments to charge a credit card. We block the front-end until the money is taken. AKA tight-coupled calls.
Loose-coupled services leverage Journal Readers to pull from Journals at their own pace and (yea, verily) never affect others who are also pulling.
To continue with the commerce illustration, assume an Order was previously created and paid for (ie. the tight-coupled processing wherein the Orders->Bills->Payments calls happened)
It is now time for the loose-coupled processing to occur as shown below:
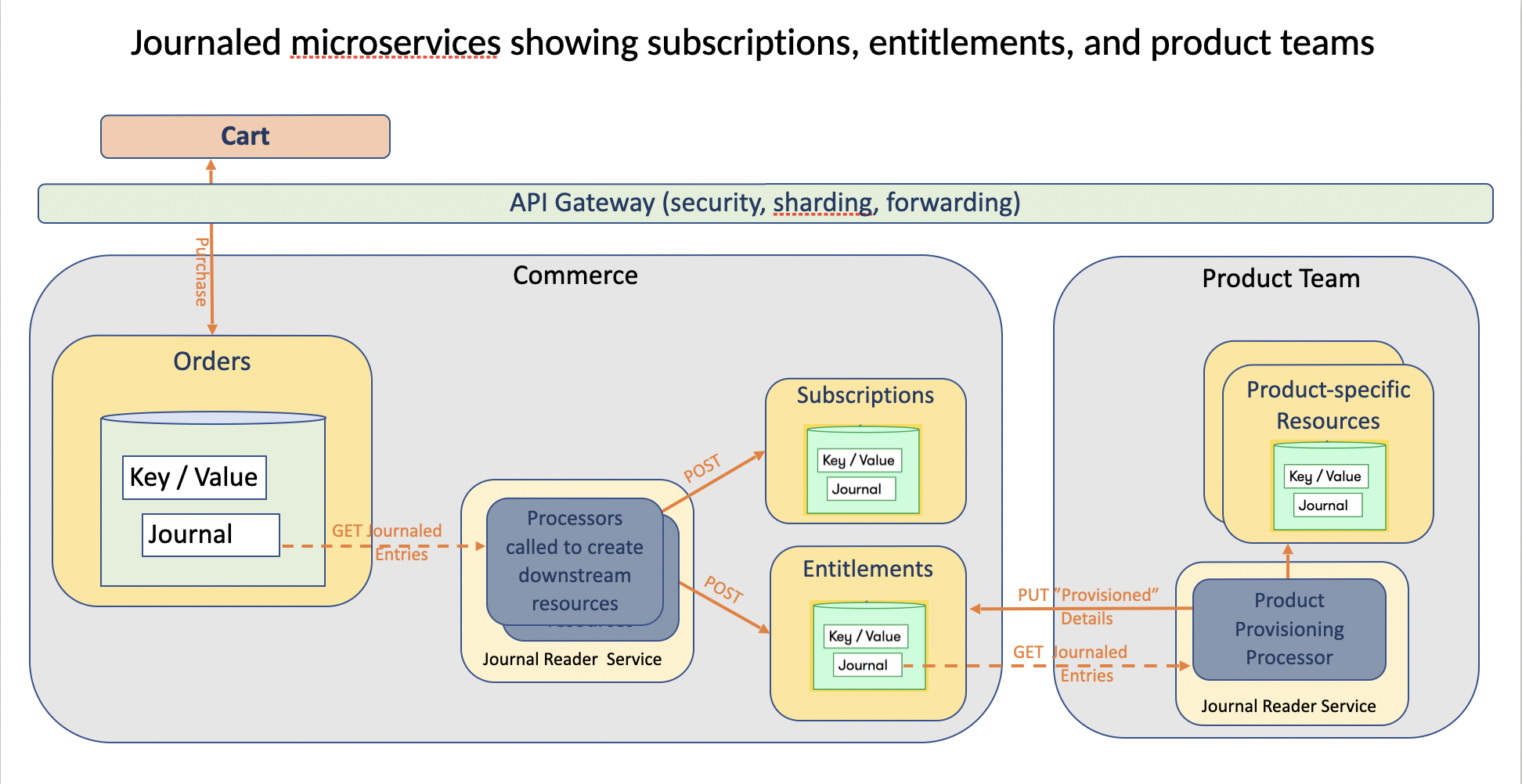
An Orders Journal Reader pulls from the Orders service’s journal and then calls 2 processors:
- One that knows when/how to build Entitlements
- One that knows when/how to build Subscriptions
Entitlement Building Processor: For every new order created that has successfully been billed (AKA funded/paid for), this processor will call the Entitlements Service (noun) to POST (ie. create) a new Entitlement that indicates a customer is authorized to use a product. Downstream the products teams have an Entitlements Journal Reader that is pulling new (or updated) entitlements to kick off provisioning for the customer.
Subscription Building Processor: For every new product purchased that requires cyclical billing (monthly / annual), this processor will call the Subscription Service (noun) to POST (ie. create) a new subscription. The subscription created is used to drive ongoing billing. Very likely a billing system reads from this journal (not shown).
Real-world examples:
- Buying an app from an app store is a one-and-done payment sort of transaction that requires only an entitlement.
- Buying a domain that is billed yearly is an example that requires both an entitlement and a subscription.
(Note 1: In the interest of simplicity, I did not show a failure with Quarantine processing. If there is enough interest, I may be convinced to write a follow-up, deep-dive article on the Journal Reader internals. Note 2: I also did not show a Processor inserting into a data pond/lake. The only difference in the image would be a Processor issuing SQL Insert/Update/Delete calls to a database engine rather than issuing REST verbs to a microservice.)
So that defines the basics of Journal Readers and how to use them.
We have discussed 3 types of services so far. All built on top of simple relational databases, which can be used in any cloud or on-prem dependent on your company’s need for scale, failover semantics, cost management, etc.
That original Microsoft architecture team explicitly stated (in their epiphany-reveal meeting): We know we are going to have relational databases in the mix. That is a given. How far can we push only having those vs all of these other systems that raise both complexity and risk of downtime?
The answer, as it turns out, was (and is still) “pretty dang far”.
Btw, a subsequent epiphany both of my last two teams came to may also interest you:
The mix of nouns and journal readers completely eradicated our need for both pub/sub and queuing systems. We stopped using cloud functions too.
Why?
Because converting those to Journal Reader processors provided a much stronger semantic AND added the ability to deploy and run them anywhere.
People sometimes talk about data center agnosticism, but few achieve it. This is the a way.
Not bad, eh?
Next up: The final musketeer of the four - the lowly Verb Service. I’m kidding, they are super useful.
Next chapter! We are almost done.
